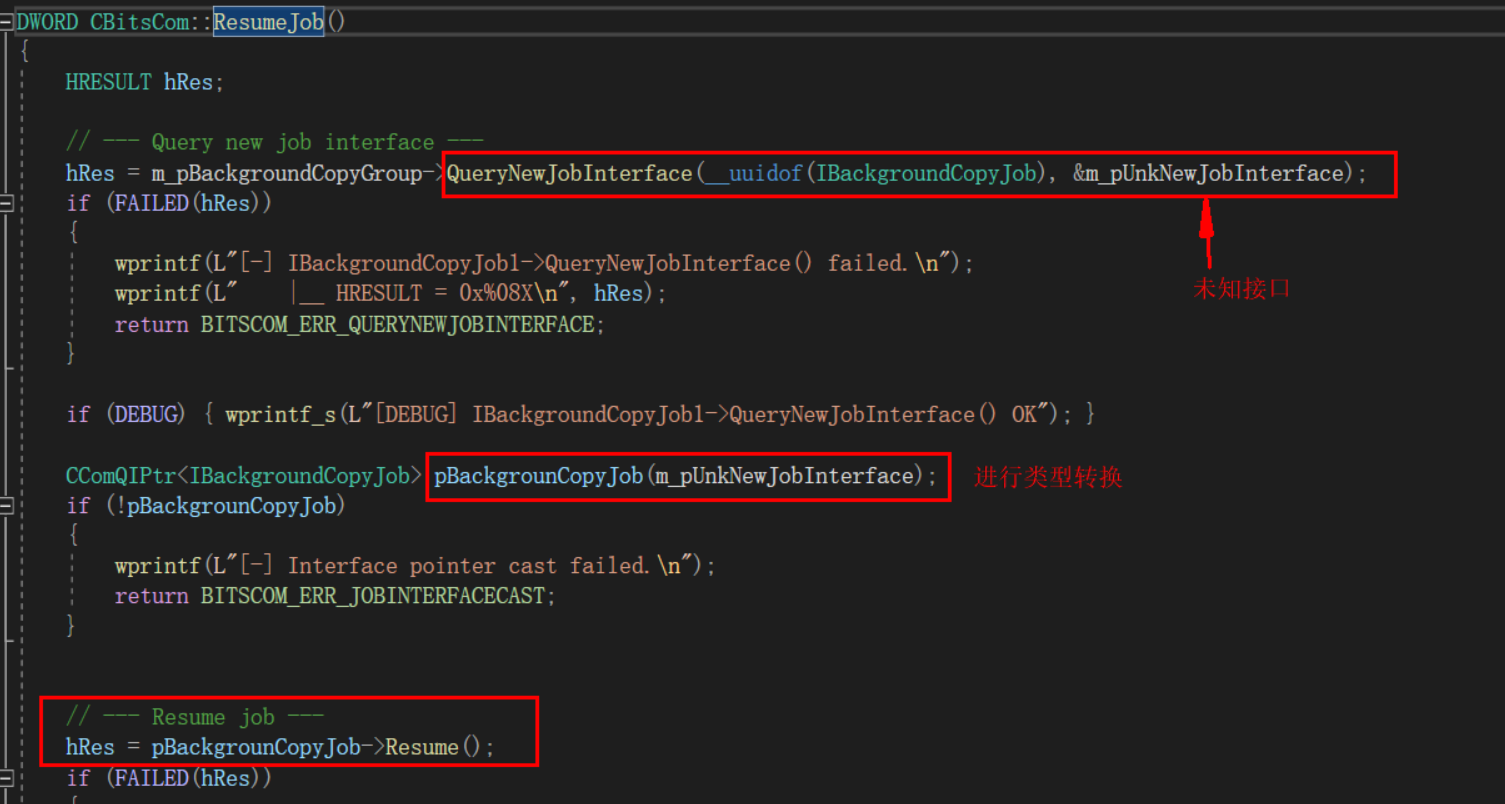
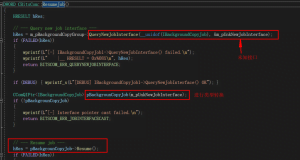
upload_73568ca92ed19a3713ad199d824d62ea 2024-2-12 16:19 | 19 | 0 | 0 字 | 几秒读完 赞赏 豆 暂无评论 发送评论 编辑评论 正在回复 的评论 : 取消回复 Markdown 发送 编辑 取消 |´・ω・)ノヾ(≧∇≦*)ゝ(☆ω☆)(╯‵□′)╯︵┴─┴ ̄﹃ ̄(/ω\)∠( ᐛ 」∠)_(๑•̀ㅁ•́ฅ)→_→୧(๑•̀⌄•́๑)૭٩(ˊᗜˋ*)و(ノ°ο°)ノ(´இ皿இ`)⌇●﹏●⌇(ฅ´ω`ฅ)(╯°A°)╯︵○○○φ( ̄∇ ̄o)ヾ(´・ ・`。)ノ"( ง ᵒ̌皿ᵒ̌)ง⁼³₌₃(ó﹏ò。)Σ(っ °Д °;)っ( ,,´・ω・)ノ"(´っω・`。)╮(╯▽╰)╭o(*////▽////*)q>﹏<( ๑´•ω•) "(ㆆᴗㆆ)😂😀😅😊🙂🙃😌😍😘😜😝😏😒🙄😳😡😔😫😱😭💩👻🙌🖕👍👫👬👭🌚🌝🙈💊😶🙏🍦🍉😣Source: github.com/k4yt3x/flowerhd 颜文字Emoji小恐龙花! × ×